
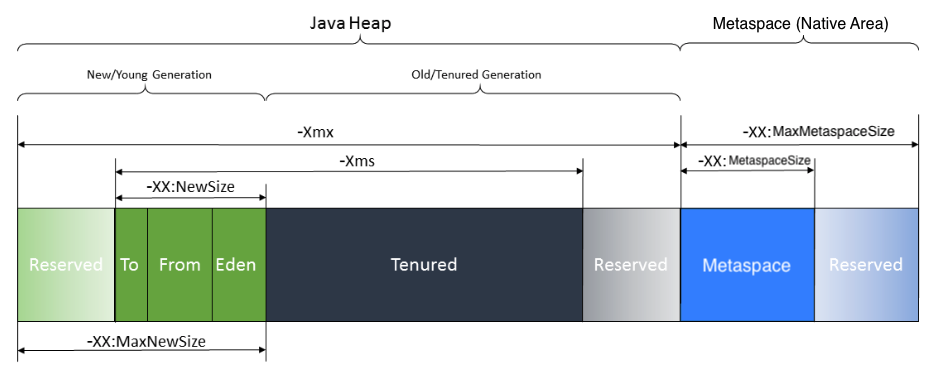
PermGen은 자바 8에서 Metaspcae로 대체됐다. 이미지 출처: https://help.sap.com/
읽기 전 주의사항(그림을 보는 법)
그림을 그리다보니 Stack에 있는 동그라미 모양과 힙 메모리에 있는 동그라미 모양이 동일한 그림들이 많이 있습니다.
이건 둘이 동일한 메모리를 의미하는 게 아니라 그냥 스택에서 힙을 참조한다는 걸 그린 건데,
사실 둘의 모양을 다르게 그려야하는데 아무 생각없이 복붙해서 그리다보니 이렇게 그리게 되었고…
되돌리기에는 너무 많이 그림을 그려놔서(히스토리 추적이 안 되게 막 그려서…) 귀챠니즘으로 인해 그림을 수정하지 않았습니다.
이 점 참고하셔서 보시길 바랍니다!
들어가기에 앞서

이 글은 이일웅 님께서 번역하신 자바 최적화란 책을 읽던 도중 공부한 내용을 정리한 글입니다.
절대 해당 책의 홍보는 아니며 좋은 책을 써준 사람과 번역해주신 분께 진심으로 감사하는 마음에 썼습니다.
자바는 C언어와 달리 프로그래머가 일일이 쓰지 않는 메모리(가비지)를 회수할 필요가 없게 끔 가비지 컬렉터가 알아서 열일한다.
자바의 모든 가비지 컬렉션에는 Stop the World(어플리케이션 스레드를 모두 멈추기 때문에 어플리케이션이 멈추게 된다.)가 발생하고 GC 쓰레드만 열일하게 된다.

죠죠의 기묘한 모험이 떠오르는 건 왜일까... 출처: https://www.youtube.com/watch?v=_cNXjmuhCCc
저수준 세부를 일일이 신경쓰지 않는 대가로 저수준 제어권을 포기한다는 사상이 자바의 핵심이다.
자바는 블루 컬러(주로 생산직에 종사하는 육체 노동자) 언어입니다.
박사 학위 논문 주제가 아니라 일을 하려고 만든 언어죠.
— 제임스 고슬링(자바의 아버지) —
즉, 일일이 메모리 해제하는 걸 ‘박사 학위 논문 주제’ 급의 어려운 일이라고 자바에서 여기는 것이다.
이런 어려운 일은 우리가 할테니 너희는 일을 해라!(비즈니스 로직이나 짜라!) 이런 뉘앙스 같다.
GC는 아래 두 가지 원칙을 준수해야한다. (프로그래머가 일일이 메모리 해제하다간 이런 유형의 휴먼 에러가 발생한다는 걸 보여준다.)
- 반드시 모든 가비지(쓰지 않는 메모리)를 수집(free)해야한다.
메모리만 엄~청 빵빵하다면 가비지가 많더라도 굳이 메모리 해제할 필요가 없다.
사실 GC도 메모리가 부족할 때만 수행한다. - 살아있는 객체(접근 가능한 객체)는 절대로 수집해선 안 된다.
C언어에서는 살아있는 객체(접근 가능한 객체)를 해제하면 Dangling pointer가 만들어지고, 어플리케이션이 뻗거나 해당 메모리에 다른 데이터가 할당돼서 해당 데이터를 더럽히는 등의 버그가 발생하게 된다.
자바에서는 살아있는 객체를 수집해가면 나중에 참조하는 쪽에서 NPE(NullPointerException) 등등이 발생할 가능성이 높다.
Mark and Sweep Algorithm
자바의 GC 알고리듬의 기본은 Mark(살아있는 객체를 표시) and Sweep(쓸어담기) 알고리듬이다.

GC 루트(스택 프레임, 전역 객체 등등과 같이 메모리 풀 외부에서 내부를 가리키는 포인터)로부터 살아있는 객체(접근 가능한 객체)를 찾는다.

살아있는 객체를 찾으면 mark bit를 true(혹은 1)로 세팅한다.
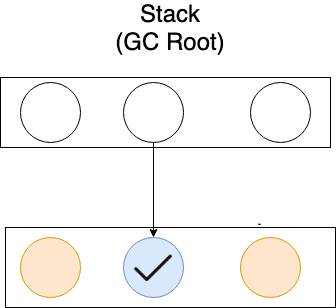
모든 객체에 대해 마크가 끝났으면 이제 mark bit가 false(혹은 0)인 객체를 찾는다.

mark bit가 false(혹은 0)인 객체는 죽은 객체(접근 불가능한 객체)이므로 가비지 컬렉터가 수거해간다.
Weak Generational 가설
JVM 및 유사 소프트웨어에서 객체 수명은 이원적 분포 양상을 보인다.
대부분의 객체는 아주 짧은 시간만 살아있지만, 나머지 객체는 기대 수명이 훨씬 길다.
이 법칙은 사람들이 실제 실험과 경험을 토대로 얻어냈다.
따라서 GC의 대상인 힙은 아래 두 가지가 핵심이라는 결론이 나왔다.
- 젊은 객체를 빠르게 수집할 수 있도록 설계해야한다.
- 늙은 객체와 단명 객체를 떼어놓는 게 가장 좋다.
Hotspot VM은 Weak Generational 가설을 활용해 아래와 같은 규칙을 만들었다.
- 객체마다 generational count(객체가 지금까지 무사통과한 가비지 컬렉션 횟수)를 센다.
- 새로운 객체는 Young Generation이라는 공간에 생성된다.
- 장수했다고 할 정도로 충분히 오래 살아남은 객체들은 별도의 메모리 영역(Old Generation 또는 Tenured Generation)에 보관된다.
또한 Weak Generational 가설 중에 ‘늙은 객체가 젊은 객체를 참조할 일은 거의 없다.’는 내용도 있는데 아예 없는 건 아니므로
Hotspot VM에서는 카드 테이블(JVM이 관리하는 바이트 배열로 각 요소는 Old Generation 공간의 512 바이트 영역을 가리킨다.)이라는 자료구조에 늙은 객체가 젊은 객체를 참조하는 정보를 기록한다.
따라서 Young Generation의 GC가 수행될 때 늙은 객체가 젊은 객체를 참조하는지도 확인해봐야한다.
하지만 이 때는 늙은 객체를 전부 뒤져보는 게 아니라 카드 테이블만 뒤져보면 돼서 GC의 수행 속도를 높여준다.

또한 메모리의 raw address를 가지고 데이터에 접근(역참조) 가능한 C언어 같은 언어는 이렇게 이분법적으로 메모리 영역을 나눈 구조와 맞지 않는다.
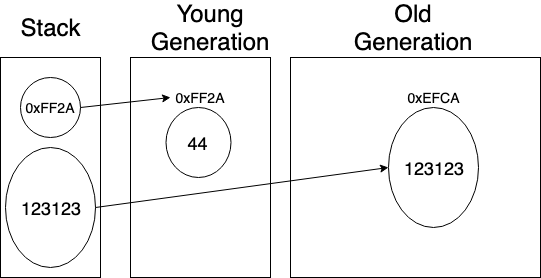
Young Generation에서 Old Generation으로 이동한 데이터는 메모리의 raw address도 바뀔텐데, 해당 raw address로 역참조를 했을 때 메모리 재할당으로 인해 다른 값이 튀어나올 가능성이 높기 때문이다.
다행히 자바는 메모리의 raw address를 사용하지도 않고, offset 연산자(. 연산자)만으로 필드나 메서드에 액세스 할 수 있기 때문에 이런 문제로부터 자유롭다.
Young Generation
Weak Generational 가설에 따라 단명하는 젊은 객체들만 모아놓은 공간이다.
대부분의 객체가 Young Generation에서 사망하시고, 새로 생성된 객체가 할당되기 때문에 GC가 자주 일어나는 영역이다.
GC가 일어나는 동안 Stop the World가 발생하는데 이 빈도가 매우 잦기 때문에 Young Generation의 GC는 수행 시간이 짧아야한다.
수행 시간이 짧으려면 수거해가는 객체의 수를 줄이면 되고, 객체의 수를 줄이려면 영역의 사이즈를 적당히 줄이면 된다.
수행 시간이 짧은 GC이기 때문에 Minor GC라고 부르는 게 아닐까?
Young Generation 사이즈를 지정하는 JVM flag는 -XX:NewSize와 -XX:MaxNewSize이며
-XX:NewRatio 속성을 통해 Old Generation 사이즈와 Young Generation 사이즈의 비율을 정할 수 있다.
예를 들어 -XX:NewRatio=3으로 지정하면 1:3=Young:Old 라고 보면 된다.
(Young은 힙 메모리의 1/4를 먹고, Old는 힙 메모리의 3/4를 먹게 되는 것이다.)
The parameters NewSize and MaxNewSize bound the young generation size from below and above.
Setting these to the same value fixes the young generation,
just as setting -Xms and -Xmx to the same value fixes the total heap size.
This is useful for tuning the young generation at a finer granularity than the integral multiples allowed by NewRatio.
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html
-XX:NewRatio 파라미터보다는 -XX:NewSize와 -XX:MaxNewSize의 사이즈를 동일하게 설정하는 게 튜닝하는데 더 좋다고 한다.
아마 동일하게 설정하는 이유는 해당 영역의 사이즈가 동적으로 줄어들고 늘어나게 되면, GC에도 영향을 미치고 기타 Ratio 관련 설정을 재계산해야되기 때문에 성능에 영향을 미치지 않기 때문 아닐까…?
또한 Young Generation의 GC는 자주 일어나기 때문에 수행 시간이 매우 짧아야하니 적어도 Old Generation의 사이즈보다 적게 할당하는 게 일반적이라고 한다.
다만 객체의 수명이 긴 객체들이 많거나 새로운 객체의 할당이 별로 없는 객체의 경우는 Young Generation의 사이즈를 좀 더 과감하게 줄이는 등 케이스 바이 케이스로 사이즈를 정해야할 것 같다.
이 모든 결정은 추측이 아닌 모니터링을 통해 할당 비율이라던지 기타 등등의 데이터들을 수치화해서 정확한 데이터 기반으로 의사 결정을 내려야할 것이다. (말이 쉽지 ㅠㅠ 어떻게 하는지도 모른다…)
Eden Space
Young Generation의 일부분이다.

새롭게 생성된 객체의 용량이 Eden Space의 용량보다 큰 경우를 제외하고는 Eden 영역에 할당된다.

그러다가 새롭게 할당할 객체의 메모리 확보를 하지 못한 경우, 즉 Eden 영역이 꽉 찬 경우에 Minor GC를 수행하게 된다.

이 때 GC를 수행하게 되면 메모리 단편화가 생기게 되고 이로 인해 객체를 할당할 전체적인 용량은 확보됐지만 연속된 메모리 공간이 없게 된다.
OS 레벨에서는 연속된 메모리 공간에 할당하지 않고 쪼개서 할당해도 되긴 하지만 할당하는 데도 오랜 시간이 걸리고, 데이터를 불러올 때도 순차적인 접근이 아니기 때문에 오래 걸리게 된다.
또한 JVM의 메모리 할당은 알아두면 좋을 상식에도 나오다시피 bump-the-pointer라는 기술을 써서 저렇게 중간에 메모리를 할당하는 일은 없다.

아니면 GC 이후에 메모리 Compaction을 수행해야하기 때문에 오버헤드가 발생할 수 밖에 없다.
Survivor Space
위에서 언급한 Eden 영역에서 GC로 인해 생기는 오버헤드를 줄이고자 생긴 영역이다.
이 영역 또한 Young Generaion의 일부이다.
Survivor 영역은 동일한 사이즈의 두 개의 영역으로 구분되는데 각각의 이름은 from과 to이다.
(VisualVM 같은 모니터링 툴에는 S0, S1으로 표시되곤 한다.)

Eden 영역에서 생존한 객체들이 Survivor 영역의 연속된 메모리 공간으로 넘어오게 되고

Eden 영역은 싹 비우게 됨으로써 Eden 영역의 제일 처음부터 할당하면 되므로 Eden 영역의 메모리 단편화 문제를 해결했다.
또한 -XX:SurvivorRatio 속성을 통해 Eden Space 사이즈와 Survivor Generation 사이즈의 비율을 정할 수 있다.
예를 들어 -XX:SurvivorRatio=6으로 지정하면 1:6=Survivor:Eden 라고 보면 된다.
(Suivovr는 Young Generation의 1/7를 먹고, Eden은 Young Generation의 6/7를 먹게 되는 것이다.)
즉, 두 Survivor 영역의 합보다 Eden 영역의 메모리가 더 크다.
(생존해서 Survivor 영역에 존재하는 객체보다 새롭게 생성돼서 Eden 영역에 할당되는 객체가 훨씬 많으므로…)
You can use the parameter SurvivorRatio can be used to tune the size of the survivor spaces, but this is often not important for performance.
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html
퍼포먼스에 영향을 주는 경우는 드물다고 적혀있지 않으니 굳이 쓸 필요는 없을 것 같다.
Survivor Space는 왜 2개일까?

그 이유는 Minor GC의 대상이 Eden에만 국한되는 게 아니라 Survivor 영역까지 Minor GC를 하기 때문이다.
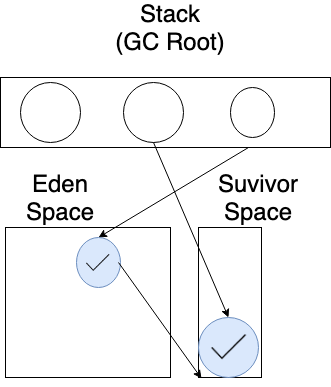
Survivor 영역을 Minor GC를 수행하면 어떻게 될까? Eden 영역만 존재할 때와 마찬가지로 Survivor 영역에도 메모리 단편화가 존재하게 된다.
알아두면 좋을 상식에도 나오다시피 bump-the-pointer라는 기술을 써서 중간에 빈 공간이 있더라도 해당 공간에 할당하지 않는다.
그럼 Survivor Space의 단편화를 없애려면 어떻게 하면 될까?

Eden 영역에서 Survivor 영역을 만든 것과 같이 새로운 영역을 추가하면 된다!
따라서 새롭게 영역을 추가하다보니 Survivor Space가 두 개가 된 거다.
Minor GC
그럼 이제 Young Generation에서 일어나는 Minor GC에 대해서 알아보자.
(물론 JVM 플래그를 어떻게 주느냐에 따라서 Minor GC의 알고리듬이 달라질 수 있고, 여기서 설명하는 Minor GC의 알고리듬은 아주 간단하고 기본적인 수준에서 설명하고 있다.)
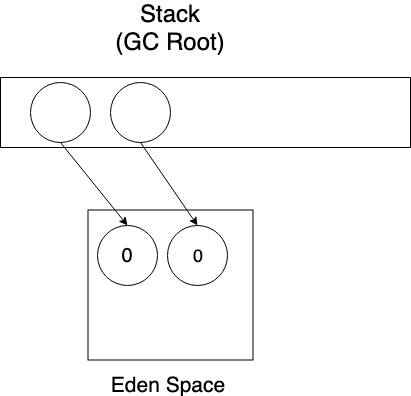
새롭게 생성된 객체는 전부 Eden Space에 할당된다. 이 때 객체의 generational count는 0이다.
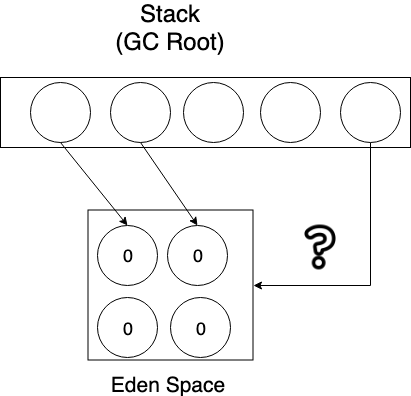
새롭게 생성된 객체를 또 할당하려는데 Eden Space에 할당할 공간이 없으면 Minor GC를 수행하게 된다. 이제부터 Stop the World의 시작이다.

Eden 영역에 할당된 객체를 순회하면서 GC 루트로부터 접근 가능한 객체만 mark를 한다.

생존한 모든 객체(mark 당한 객체)는 Survivor Space로 복사한다.
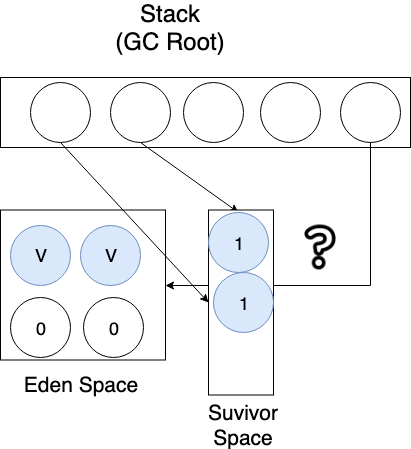
GC로부터 살아남은 객체는 이제 generational count가 1로 증가한다. (이렇게 generational count를 1씩 늘리는 프로세스를 aging이라고 부른다... 나이를 먹어가는 ㅠㅠ)

Eden Space를 비운다. (Sweep) 이제 Stop the World가 끝났다.

이제 Eden Space의 공간 확보가 됐으니 새롭게 생성된 객체를 Eden Space에 할당한다.

새롭게 생성된 객체를 또 할당하려는데 Eden Space에 할당할 공간이 없으면 Minor GC를 수행하게 된다. (Stop the World의 시작)

이번에는 Eden 영역과 더불어 Survivor Space에 할당된 객체를 순회하면서 GC 루트로부터 접근 가능한 객체만 mark를 한다.

Survivor Space에서 생존하지 못한(mark 당하지 않은) 모든 객체를 수거해간다. (Sweep)
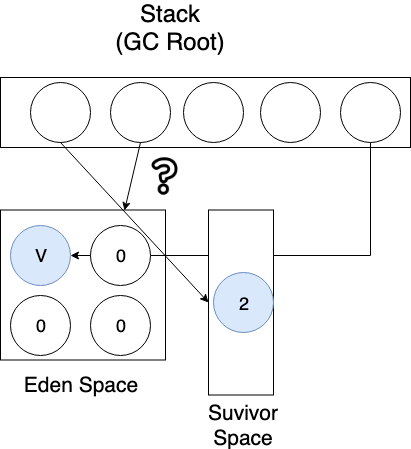
이 때 Survivor Space에서 생존한 객체는 generational count가 2로 증가한다.

Eden Space에서 mark된(생존한) 객체는 Survivor Space로 복사된다.

이 때 Eden에서 복사되는 객체는 generational count가 1로 증가한다.

이제 Eden Space를 비워준다, Sweep. (Stop the World의 끝)
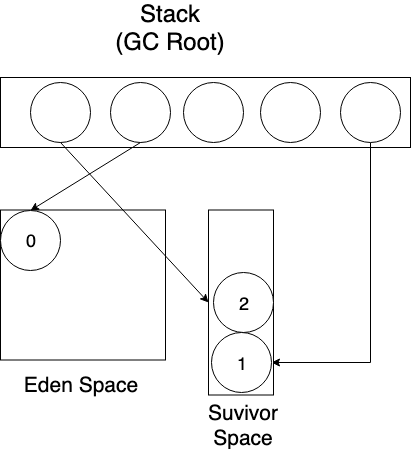
이제 새로운 객체를 할당하면 된다.

위 과정들을 반복하다가 또 Eden Space가 꽉 차서 GC를 수행하게 됐다고 가정하자. (Stop the world의 시작)
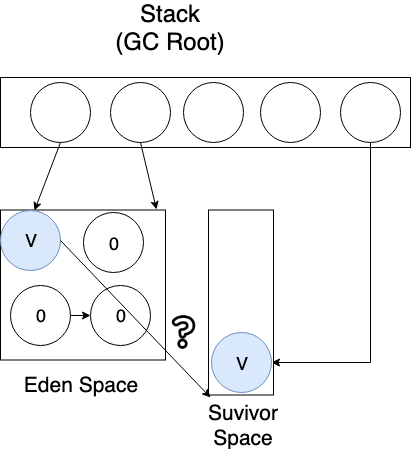
모든 과정을 마치고 이제 Eden Space에서 생존한 객체들을 Survivor Space로 옮기려고 했더니 Survivor Space에 연속된 메모리 공간을 확보하지 못해서 더 이상 메모리 할당이 불가능하다고 가정해보자.

이 때 From Survivor Space에서 생존한 모든 객체들을 To Survivor Space의 연속된 공간에 먼저 옮기고, 그 후에 Eden Space에서 생존한 객체를 To Survivor Space의 연속된 공간에 옮긴다.
To Survivor Space에 Eden Space에 있는 내용보다 From Survivor Space에 있는 내용을 먼저 복사하는 이유는
generational count가 적은 객체(Eden Space에 거주중인 객체들)보다 generational count가 높은 객체(From Survivor Space에 거주중인 객체들)의
수명이 더 길 가능성이 높기 때문이다. (Weak Generational 가설에 의해…)
수명이 더 길 가능성이 높은 메모리를 먼저 배치하는 이유는 메모리의 단편화를 줄이기 위함이다.

생존한 모든 객체를 옮겼으므로 From Survivor Space와 Eden Space를 비운다.
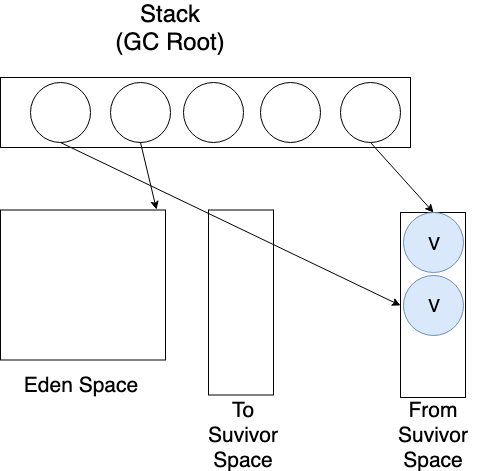
기존 From Survivor Space의 역할을 To Survivor Space가 대신하게 됐으므로 둘의 이름을 바꾼다. (Stop the World의 끝)

GC가 끝났으므로 새로운 객체를 Eden Space에 할당한다.
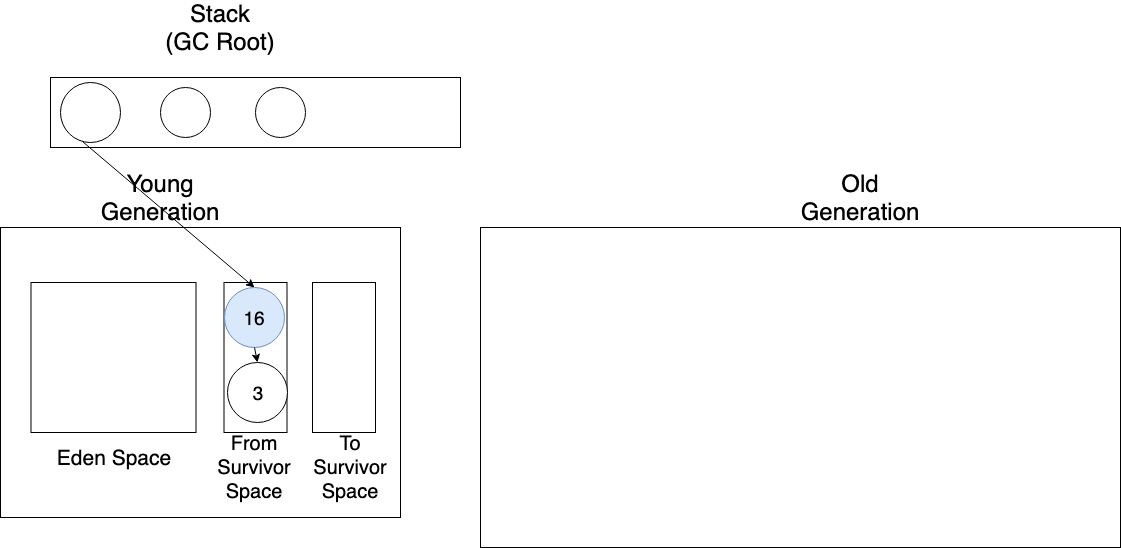
위 과정을 반복하다가 생존을 반복한 From Survivor Space에 있는 객체가 적당히 나이를 먹었다고 가정해보자.

그럼 해당 객체는 Promotion(승진)을 한다.
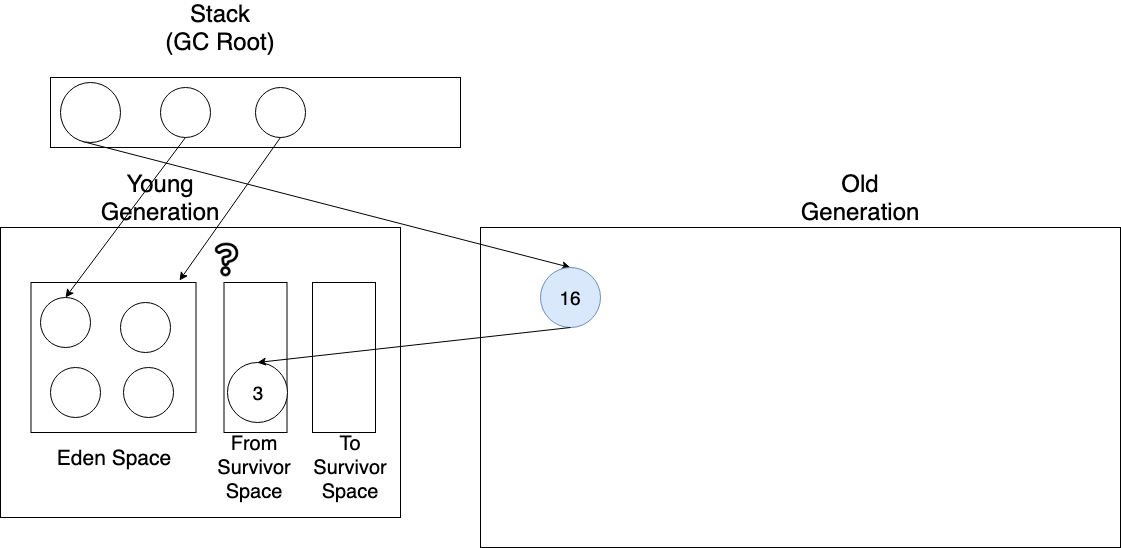
그러다 다시 Minor GC를 해야되게 됐다.
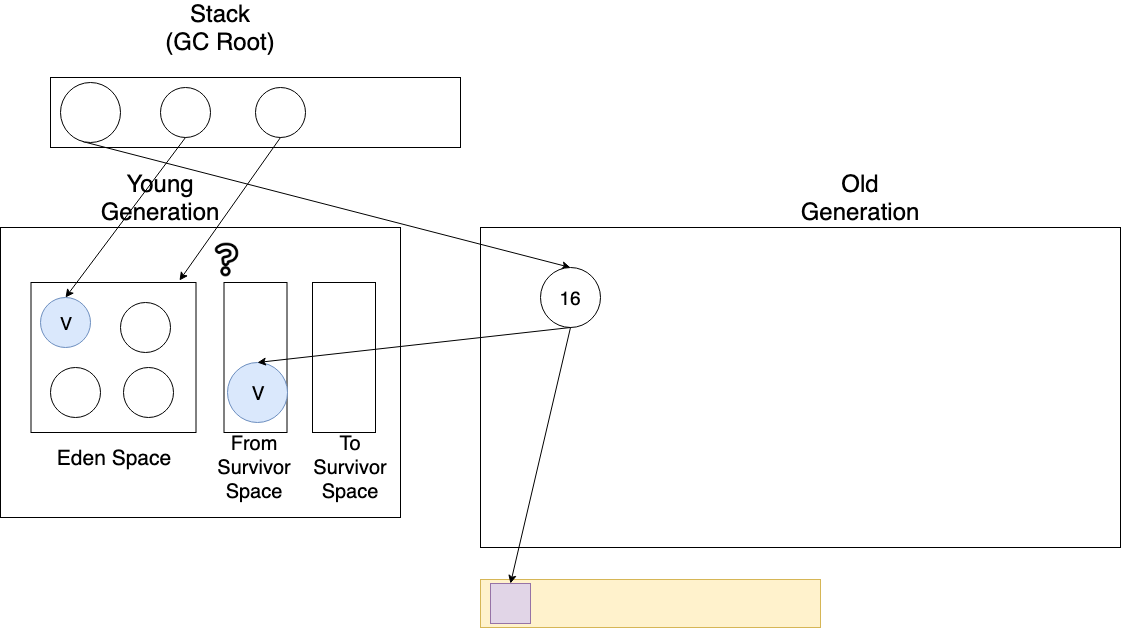
이 경우에는 흔치 않게 Old Generation에서 Young Generation을 참조하고 있어서 GC 로직이 복잡해보이는데 간단하게 카드 테이블에 저장된 객체만 추가로 검사해서 Old Generation에서 Young Generation으로 참조 중인 객체를 쉽고 빠르게 찾을 수 있다.
Promotion
아래 나오는 그림에서 동그라미 안의 숫자는 객체의 나이(객체가 GC로부터 살아남은 횟수)를 의미한다.
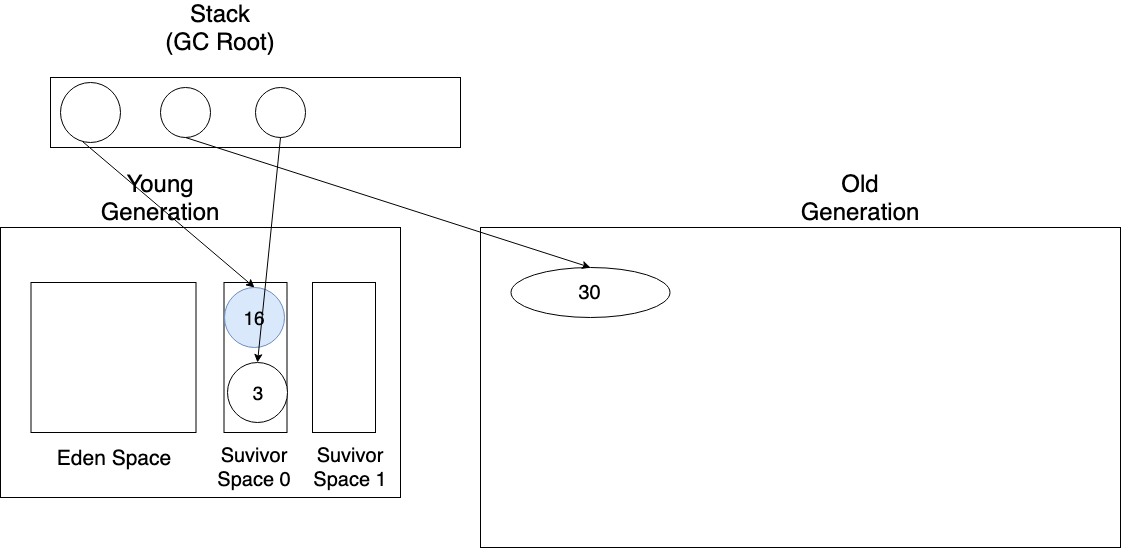
Promotion(승진)은 Young Generation에서 적당히 나이를 먹어서(GC로 부터 살아남아서 계속해서 generational count가 늘어나서 적당한 generational count가 됐음을 의미)

이제 Old Generation으로 갈 나이가 됐으니 Old Generation으로 이동하는 걸 의미한다.
generational count가 어느정도 있으려면(짬밥을 어느정도 먹었으려면) 당연히 Survivor Space에 있는 객체가 이동됨을 의미한다.
적당한 나이는 -XX:InitialTenuringThreshold와 -XX:MaxTenuringThreshold 파라미터로 정할 수 있다.
(Old 영역으로 승진하는 객체의 갯수나 비율이 많아지면 자동으로 TenuringThreshold를 늘리는 원리인지 뭔지 잘 모르겠다…)
Premature Promotion
적당한 나이(TenuringThreshold)를 먹지 않았는데 어쩔 수 없이 Old Generation으로 이동하는 행위를 premature promotion(조기 승진)이라고 부른다.
아래 나오는 그림에서 동그라미 안의 숫자는 객체의 나이(객체가 GC로부터 살아남은 횟수)를 의미한다.

주로 메모리 할당이 잦다보니 Survivor Space에 적당한 공간이 없어서
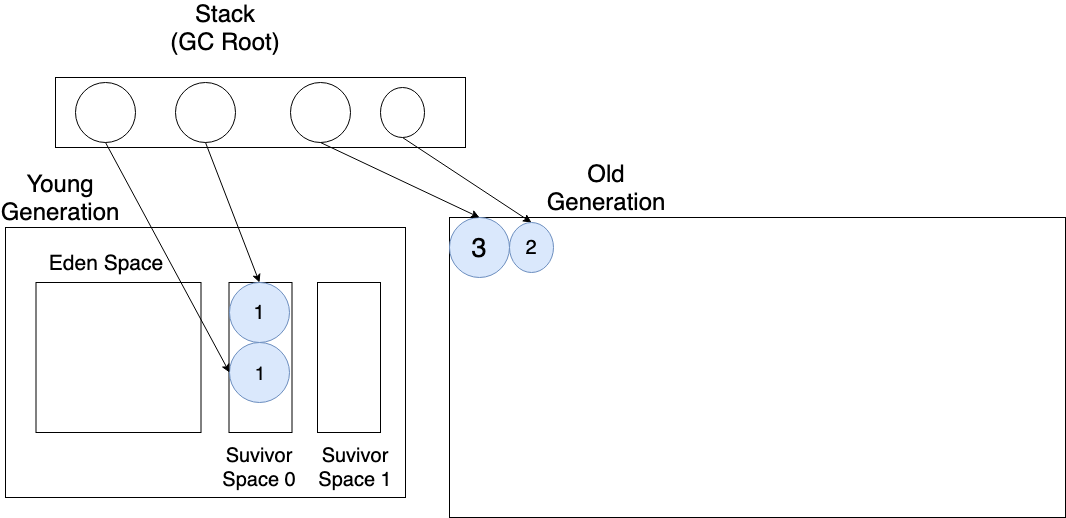
나이를 먹지 않았음에도 Old Generation으로 옮겨지는 경우도 Premature Promotion이고,

새롭게 할당될 객체의 용량이 Eden Space의 용량보다 큰 경우에는
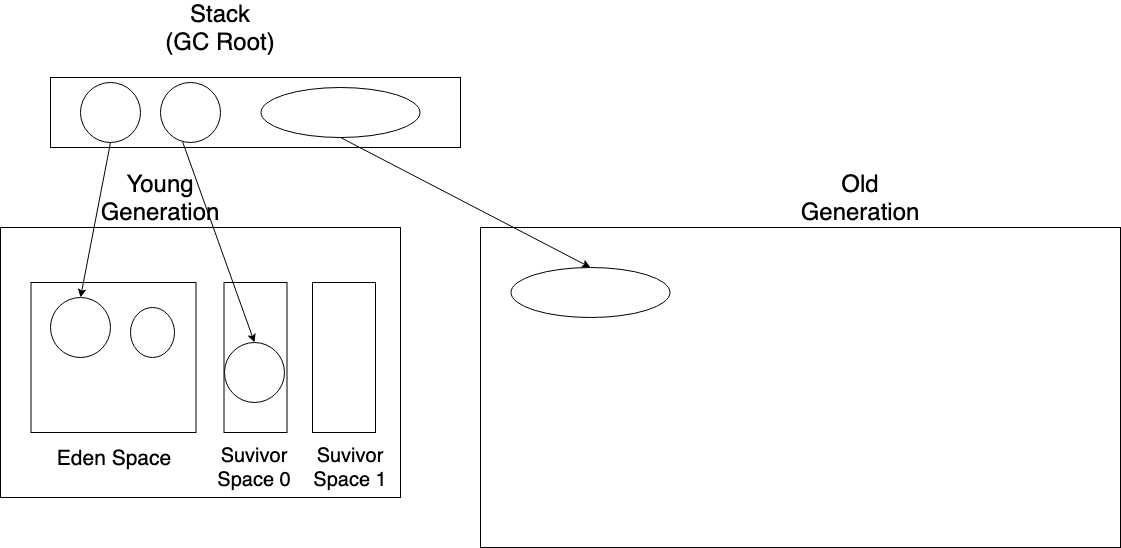
바로 Old Generation에 할당되게 되는데 이 경우에도 Premature Promotion이고,

원래 같으면 Eden Space의 내용이 From Survivor Space 영역의 바로 아래 공간에 할당되면 되는데, -XX:TargetSurvivorRatio(기본값 50)에 의해 할당되지 못하는 경우가 있다.
-XX:TargetSurvivorRatio는 Minor GC 이후의 From Survivor Space의 사용률(%)을 제한하는 옵션이다.

적당한 나이가 되지 않은 어린 객체가 Old Generation으로 이동하는 것도 Premature Promotion이다.
이 premature promotion의 경우에는 Old Generation에 놓기 때문에 Major GC 혹은 Full GC가 일어나기 전에는 회수해가지 않으며
적당한 나이를 먹지 않고 와서 단명할 가능성이 높음에도 불구하고 쓸데없이 Old Generation을 차지하고 있기 때문에
Major GC 혹은 Full GC의 발생 빈도를 늘려 어플리케이션 전반에 영향을 미치기 때문에 적절하게 Young Generation과 관련된 사이즈를 정하는 게 중요하다.
Old Generation
객체가 적당한 나이를 먹거나 조기 승진을 통해 넘어온 객체들이 존재하는 영역이다.
Tenure Generation이라고도 부른다.
해당 영역에 존재하는 객체들을 Young Generation에 있는 객체들보다 회수당할 가능성이 적다는 게 Weak Generational 가설이다.
또한 대부분의 객체가 Young Generation에서 사망하시기 때문에 Old Generation으로 오는 객체는 Young Generation에 할당되는 객체의 비율에 비해 현저히 낮다.
Major GC
Major GC 역시 Old Generation이 꽉 찼을 때 수행된다.
기본적으로 Old Generation은 메모리 할당률이 낮기 때문에 GC가 일어나는 빈도가 적다.
또한 대부분 Old Generation은 Young Generation 보다 용량을 크게 잡기 때문에 객체의 갯수도 많아서 GC 시간이 길다.
GC의 시간이 길다는 것은 그만큼 Stop the World, 어플리케이션이 멈추는 시간도 길다는 의미고 그런 의미에서 Major GC(주요한 GC)라고 이름을 붙인 게 아닐까 싶다.
또한 Old Generation은 Young Generation과 같이 Survivor Space가 존재하는 게 아니기 때문에 메모리 단편화도 신경써야하고 관리해야할 객체도 많다보니 훨씬 알고리듬이 복잡해진다.
이에 대해선 다음에 글을 써볼 예정이다.
Full GC
Minor GC + Major GC를 Full GC라고 부른다.
정확히 언제 일어나는지 모르겠지만 Old Generation GC에 대해 좀 더 자세히 공부하고 다시 작성해야겠다.
Permanent Generation
JVM의 Method Area를 Hotspot VM에서 Permanent Generation(줄여서 PermGen)으로 부르기 시작하면서 다른 VM에서도 PermGen이라고 부르는 것 같다.
PermGen은 자바 8에서 사라졌다.
PermGen에는 클래스의 메타데이터, 메서드의 메타데이터, 상수풀, static 변수 등등이 들어간다.
PermGen은 이름만 들어보면 Permanent(영구적인)가 들어가다보니 영구히 존재하는 데이터들만 저장될 거 같은데 필수는 아니지만 GC가 수행되기도 한다.
GC가 수행된다는 관점에서인지 이 영역을 힙 메모리로 보는 사람도 있는데 나는 클래스의 인스턴스가 저장되는 것도 아니고
-Xmx, -Xms와는 별개로 사이즈가 지정되다보니 힙메모리가 아니라고 생각하고 있다.
-XX:PermSize와 -XX:MaxPermSize로 사이즈를 지정할 수 있고, GC를 수행하지 않는다면 용량이 부족해질 수 있고 아래와 같은 OOME가 난다.
java.lang.OutOfMemoryError: PermGen space
이러한 에러가 나는 이유는 여러가지가 있는데 대표적으로 다음과 같다.
- collection을 static으로 만들고 계속해서 요소를 추가하는 경우(이런 실수를 범하면 절대 안된다.)
- 서버를 재시작하지 않고 변경 내역을 바로바로 반영해주는 HotDeploy를 계속해서 사용하다보면 Class와 Method의 메타데이터가 계속해서 쌓이게 되는데
서버를 주기적으로 재시작해주지 않고, 계속해서 HotDeploy 하는 경우(실서버에서 이런 경우는 거의 없을 것이다.)
Metadata
자바 8부터 PermGen의 역할을 Metadata 영역에서 맡기 시작했고 Native 영역으로 옮겨졌다. (즉 OS에서 관리한다는 의미)
PermGen 중에 일부만 Metadata 영역에서 맡기 시작했고, 상수풀이나 static 변수는 Heap 메모리로 옮겨져왔다.
즉, 개발자가 실수하기 쉽거나 변경이 잦은 내용들은 힙 메모리로 끌고와서 GC의 대상이 되게 하고, 정말 변경이 될 가능성이 적은 내용들만 Native 영역으로 옮겨버렸다.
문제는 Native 영역은 dump를 떠도 안 나와서 분석하기 힘들다는데 이럴 일은 아마 거의 없을 것이다…
Metadata에 대한 관리는 OS에서 함으로 믿고 맡겨도 된다고 생각하지만(개발자가 직접하는 것보다 낫지 않을까?),
혹시 이 쪽을 튜닝해야하거나 OOME(java.lang.OutOfMemoryError: Metadata space)가 발생한 경우에는 -XX:MetaspaceSize와 -XX:MaxMetaspaceSize 파라미터를 사용해보자.
OutOfMemoryException
주로 OOME라고 줄여부르며 메모리 공간이 부족해서 나는 예외로 어플리케이션 자체가 뻗는 현상이 발생한다.
이 예외가 발생했을 때는 메모리 릭(메모리 결함)이 발생한 경우이고 Heap 메모리나 PermGen(Metaspace) 등등의 영역이 부족할 때 발생하는데
어떤 메모리가 부족한 건지, 아니면 왜 이 오류가 났는지 Stacktrace를 찍고 사망한다.
여기서는 힙 메모리가 부족해서 OOME가 발생한 경우의 원인에 대해서만 설명하겠다.
우선 메모리가 부족하면 가비지 컬렉터는 힙메모리의 가비지 컬렉션을 수행한다.
가비지 컬렉션을 수행했음에도 불구하고 새로운 객체를 더이상 할당할 수 없는 경우에 OOME가 발생하게 된다.
이 때는 아주 급한 경우에는 일단 -Xmx와 -Xms로 메모리를 늘리고 보고,

위 두가지 설정을 주고 실행해서 재발하면 힙덤프를 생성하거나 아니면
jmap 등등으로 살아있는 서버의 힙덤프를 떠서 어디서 메모리 릭이 발생했는지 Eclipse MAT 등등으로 분석하거나
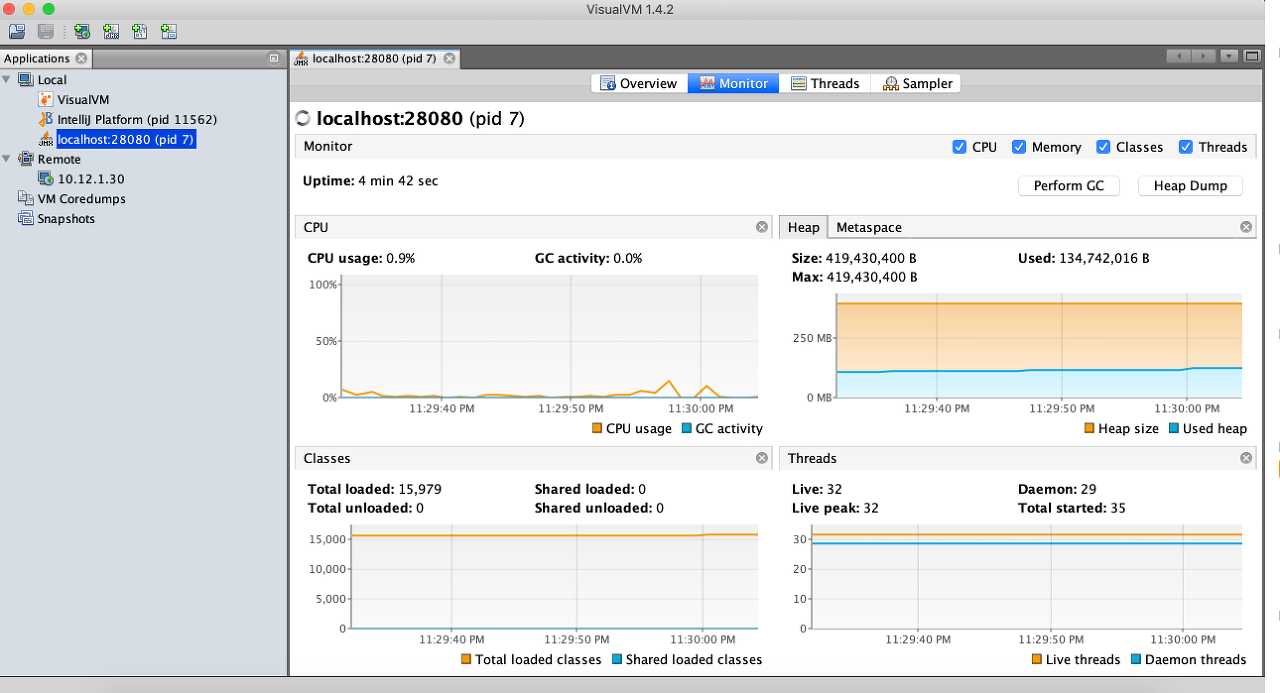
위 설정 등등을 줘서 VisualVM으로 서버에 실제로 떠있는 어플리케이션 등등을 모니터링하는 방법이 있다.
알아두면 좋을 상식
- Hotspot VM의 GC는 Arena라는 메모리 영역에서 작동한다.
- Hotspot VM은 시작 시 메모리를 유저 공간에 할당/관리한다.
따라서 힙 메모리를 관리할 때 시스템 콜을 하지 않으므로 커널 공간으로 컨텍스트 스위칭을 하지 않아서 성능 향상에 도움이 된다. - Hotspot VM은 할당된 메모리 가장 마지막의 다음 영역을 가리켜 연속된 빈 공간에 효율적으로 빠르게 할당하는 bump-the-pointer라는 기술을 사용했다.
- Hotspot VM은 멀티 스레드 환경에서 객체를 할당할 때 스레드 간의 경합 등등의 문제를 줄이고자 TLAB(Thread Local Allocation Buffer)를 사용했다.
Eden Space를 여러 버퍼로 나누어 각 어플리케이션 스레드에게 할당함으로써 자기 자신이 사용해야 할 버퍼를 바로 찾게되고, 리소스를 공유해서 생기는 문제를 없애버렸다.
만약 본인에게 할당된 TLAB가 부족할 경우에는 크기를 동적으로 조정한다.
참조 링크
- Naver D2 - Java Garbage Collection
- Naver D2 - JVM Internal
- The JVM and Java Garbage Collection - OLL Live (Recorded Webcast Event)
- JDK8에선 PermGen이 완전히 사라지고 Metaspace가 이를 대신 함.
- JDK8 적용 후, 심각한 성능저하가 발생한다면?
- JAVA8 Permanent 영역은 어디로 가는가
- Understand the OutOfMemoryError Exception - Oracle Docs
- Sizing the Generations - Oracle Docs
- Minor GC vs Major GC vs Full GC
- Useful JVM Flags – Part 5 (Young Generation Garbage Collection)
- “-XX:TargetSurvivorRatio” - Second Tenuring Condition
그 외 더 많은 거 같은데 기억이 잘 나지 않는다…
- 출처 : https://perfectacle.github.io/2019/05/07/jvm-gc-basic/
'Programming > Java' 카테고리의 다른 글
| java print api 주의 사항 (0) | 2021.01.15 |
|---|---|
| 왜 돈 연산에는 Floating-point type을 쓰면 안되나? (0) | 2020.06.30 |
| Lombok @Builder에서 method name 이용 패턴 (0) | 2020.05.21 |
| Non-blocking, Blocking (0) | 2019.03.18 |
| Asynchronous (VS Synchronous) (0) | 2019.03.18 |






