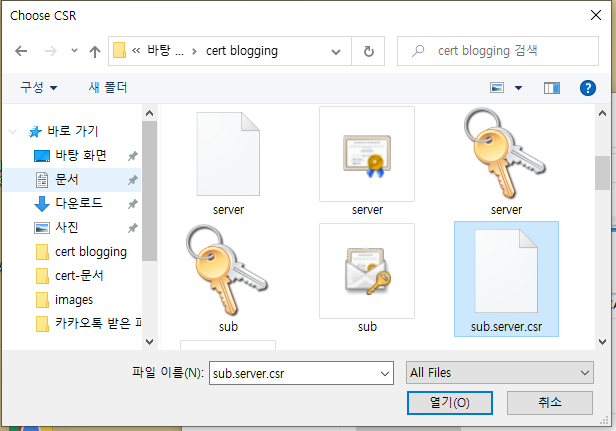
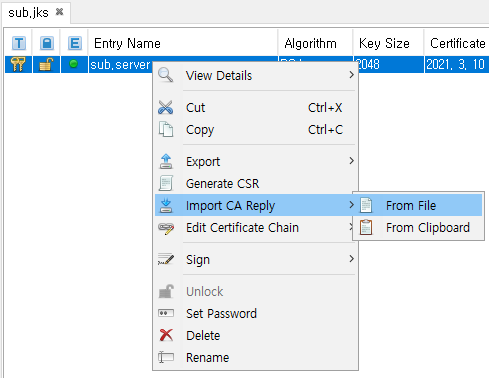
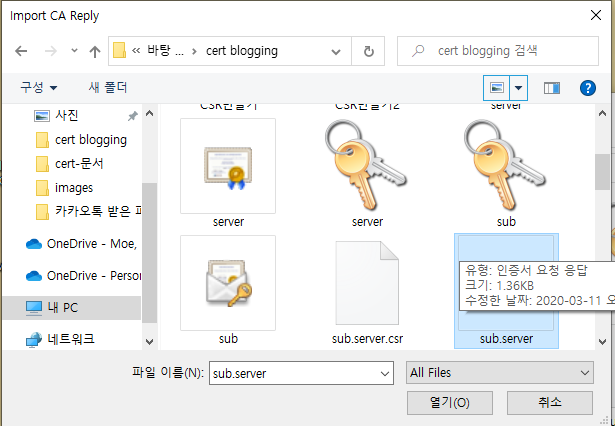
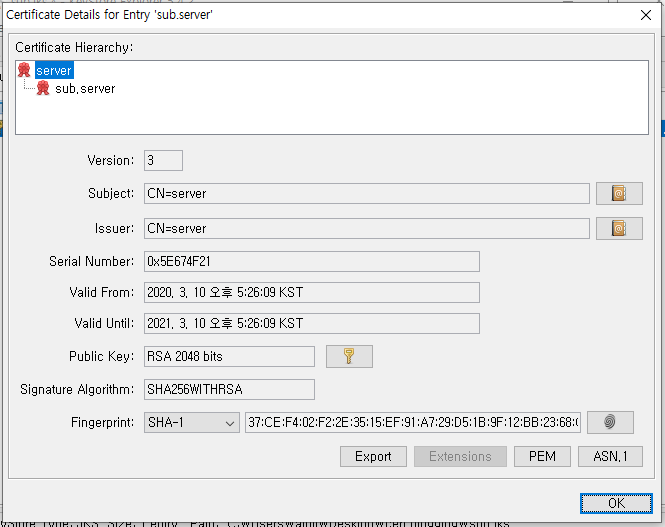
옛날에 썼던 사내 wiki들을 다시 둘러보고 있다. 예전에는 이런 것들을 고민했었고 그때는 어떤 문제들을 직면하고 있었고 어떻게 풀어내려고 시도했었는지 기억이 새록새록 나기도 한다.
wiki에는 딱 한 줄만 쓰여 있었다.
로그를 쌓을 때, 고려해야 할 것들에 대한 발표자료가 있어 공유하기 위해 등록합니다.
그런데 내 기억에는 많은 것이 들어 있었다. 이때 진행하던 프로젝트 여러 서버에서 받은 로그들이 한눈에 보기 힘들었다. 그래서 spring sleuth에 빠져있었던 시기였다. 어떻게 하면 로그를 효율적으로 남겨서 한눈에 볼 수 있을까? 를 엄청나게 고민했던 시기여서 몇 줄 되지 않는 기록에도 내 뇌세포들이 반응했다. 그래서 이 기억을 다시 블로그에 남긴다.
이러한 조직이 MSA로 가기 위하여 가장 고민해야 할 부분은 아키텍트들이다. 개발자들은 대부분 개발을 하고 공통 프레임 워크를 사용하고, 강력한 표준 준수를 규정으로 정의하여 자율성을 최대한 적게 가져갔던 Monolithic 아키텍처 대비 개발자가 거의 모든 일을 알아서 해야 하는 그리고 자 율도가 많은 MSA 특성에 맞는 시스템을 구현하기 위하여 아키텍트의 역할은 많은 변화가 필요하다. "Building microservices Sam Newman" 책에서는 아키텍트의 역할을 "진화적 아키텍트"라는 용어를 사용하여 정의하였다. 진화적인 아키텍트는 [원칙과 실천]으로 분리하여 아키텍트 역할을 정의해야 한다고 했다.
원칙 : 변하지 않는 것으로 한 프로젝트 혹은 한 회사의 아키텍처 원칙을 정의한다. 예를 들면 우리의 아키텍처는 "외부 의존성은 낮추고, 복잡성은 제거 해야 하며, 인터페이스와 데이터의 흐름은 일관성을 유지한다" 라는 원칙을 세웠다고 하 자.
실천 : 위의 원칙을 지키고자 하는 여러 아키텍처를 활용하는 것이다. 예를 들면 "표준 인터페이스는 Rest API, 통합 DB 는 사용하지 않으나 업무 종류별 회사 표준의 DB를 활용 한다" 등등. 각 시스템에 맞는 그러나 표준은 준수하는 실천을 해 야 하는 것이다.
아키텍트는 이렇게 원칙을 정의하고 실천은 알아서 하되, 이를 원칙에 맞게 조율하고 준수하게 하는 통합 아키텍트와 각 서비스에서 아키텍처를 구현하는 서비스 영역내 아키텍트로 구분하여 역할을 만들어야 한다. [출처]MSA 어플리케이션 구축 시 조직 구성은 어떻게 해야 할까요?|작성자리니
원칙을 정하고 원칙에 의해 아키텍처를 적용하면 진행방향이 흔들리지 않을 것입니다.
2. TDD
프로그램을 개발하기 전에 먼저 테스트 코드를 작성하는 것...이라고 하지만 개인적인 생각은 꼭 "먼저"일 필요는 없다이다. 이것이 test code가 필요없다는 것이 아니라 프로그래밍 시작이건 중간이건 끝나고던 배포전에만 testcode가 작성되어 있다면 된다는 것이다. 그러 나 먼저 하는 것을 추천한다. 항상 할 일을 미루면 프로그램 중에도 찝찝하고 한 번 미룬건 계속 미루기 쉽상이기 때문이다.
TDD를 통해서 얻고자 하는 최종 목적은 잘 동작하는 깔끔한 코드(clean code)이다. 이는 유지보수의 편의성, 가독성, 안정성등의 여러가 지 의미를 내포한다.
TDD 진행
과정 질문(Ask) : 테스트 작성을 통해 시스템에 질문한다.(테스트에 실패할만한 질문을 해야한다.)
응답(Response) : 테스트를 통과하는 코드를 작성해서 질문에 대답한다. (테스트에 통과할 최소의 코드만을 작성해야 한다.)
정제(Refine) : 아이디어를 통합하고, 불필요한 코드를 제거하고 모호한것을 명확히한다.
반복(Repeat) : 다음 질문을 통해 계속해서 진행해 나간다.
3. CI/CD Automation
CI (Continuous Integration)
개발자가 자신의 코드를 중앙 코드와 통합하면 자동으로 빌드되고 report가 생성된다.
이때 위의 TDD에서 작성한 test code의 coverage에 따라 영향을 받는다.
CD (Continuous Delivery)
사실상 CI의 연장선, CD를 하려면 CI가 선행되어야 한다고 봐도 무방하다.
현재 우리 회사는 Jenkins가 사용되고 있으므로 검토대상 1호이다.
4. Container Management
Kubernetes같은 orchestration tool이 하는 일이다.
하지만 현실적으로 cloud의 기능을 사용해야 할 듯 하다.
resiliency 복원력 정도로 해석할 수 있다. 다음 이야기 하는 service mesh와 함께 문제가 되는 container를 다시 동작하도록 하는 기능이 있다.
5. Service Mesh
밑에 그림 처럼 outer gateway가 아닌 inner gateway에서 적용되어야 할 부분이다.
Microservice는 SOA(Service Oriented Architecture)의 경량화 버전으로 (Service: 특정 기능의 집합, service의 범위 정의가 중요) 모놀리틱 아키텍처(monolithic architecture)를 쪼개서 독립적으로 구분합니다.
Microservice는 독립적으로 디플로이/확장될 수 있는 서비스들을 조합하여 large 어플리케이션을 구성하는 아키텍처 패턴입니다.
일반적으로 Service Discovery, API Gateway, Orchestration, Choreography, Context Boundary등의 서비스들의 조합으로 이루어져있습니다.
Netflix, Twitter, Amazon, Nike 등의 회사에서 채택한 아키텍처로 소개되면서 '14년 초반부터 현재까지 주목 받고 있습니다. 아키텍처 관련 기술 표준은 없으며 SW벤더들이 기존 제품군(SOA, PaaS, ...)을 Microservices를 지원하기 위한 플랫폼으로서 rebrand하는 추세로 전환되고 있습니다.
MSA 상세 아키텍처 패턴 분석 (gartner 자료)
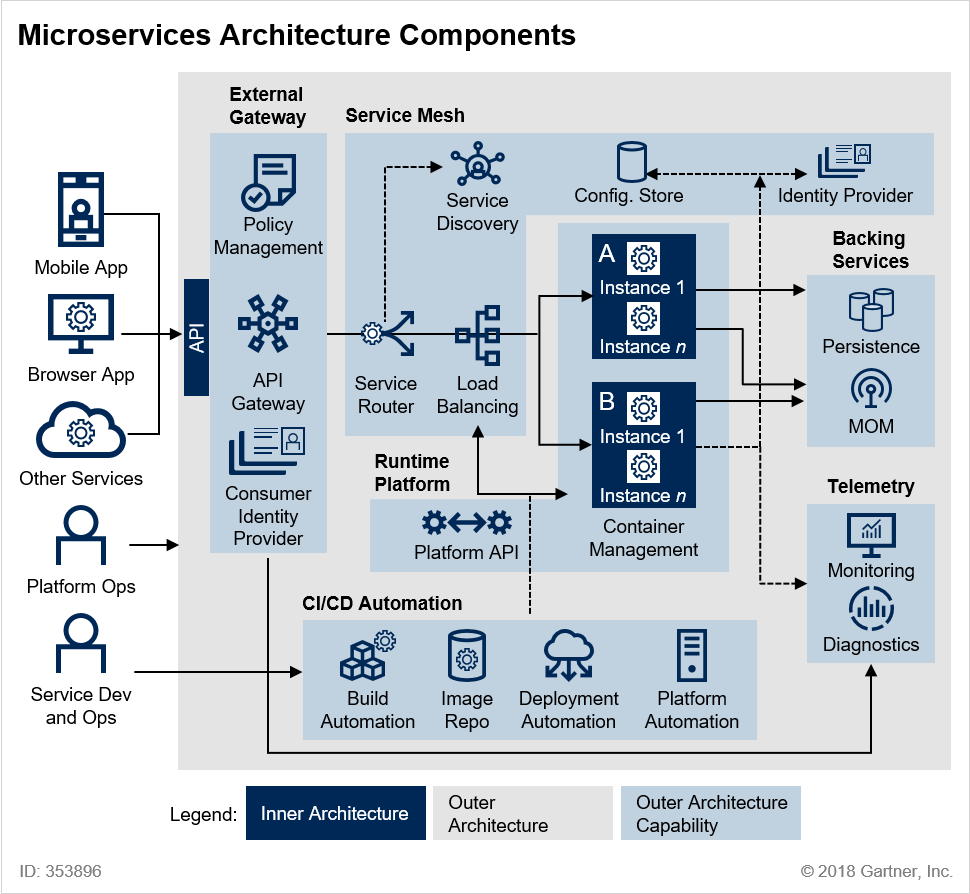
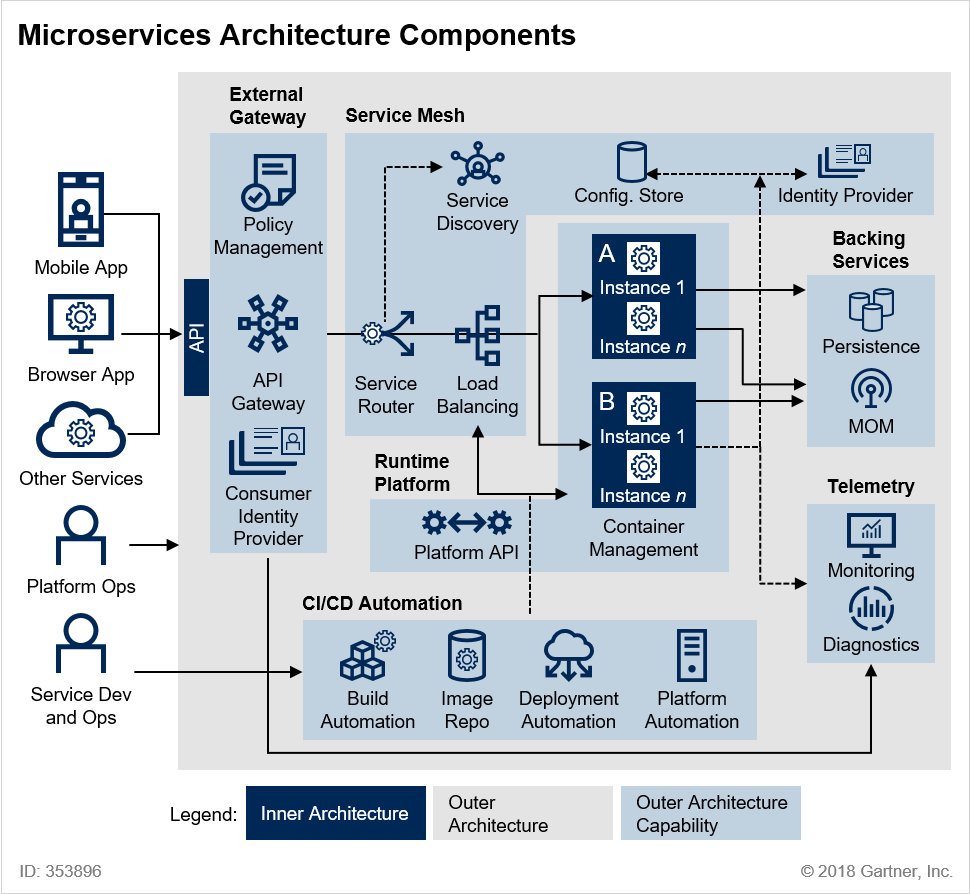
[그림 1] Microservices Architecture Components @ 2018 Gartner, Inc.
본 이미지는 Gartner에 게시된 Microservice Architecture Components입니다.
앞서 살펴보았단 표준 아키텍처(개인적인 생각)를 보다 도식화하여 상세히 풀어 놓았습니다.
㉠관리 컨테이너 :개별 서비스 인스턴스에는 작동 할 컨텍스트가 필요합니다. 가상 컴퓨터, Docker 컨테이너 또는 조정 된 프로세스로 구현 된 관리 컨테이너는 이러한 기능을 제공합니다. 이 구성 요소는 인스턴스 관리 및 조정을 제공하고 필요에 따라 새 인스턴스를 회전하며 개별 인스턴스의 수명주기를 관리합니다.
㉡외부 게이트웨이 :MSA 구현은 비즈니스 응용 프로그램 및 응용 프로그램에서 사용할 수있는 API 형태로 기능을 노출 할 수 있습니다. 서비스 외부 게이트웨이는 이러한 서비스에 대한 액세스를 관리하고 트래픽 관리 및 보안 정책을 적용하여 마이크로 서비스 환경을 보호합니다. 외부 게이트웨이 기능은 종종 API 관리 제품을 사용하여 구현됩니다.
㉢서비스 메쉬 기능 :서비스 메쉬는 서비스 간의 통신을 느슨하게 결합, 신뢰성 및 유연성을 유지하는 데 도움이되는 기능으로 구성됩니다. 이러한 기능을 통해 서비스 분리, 버전 관리 전략 지원 및 부하시 탄성 확장 성 관리가 가능합니다.
서비스 라우팅 : 클라이언트 응용 프로그램에서 또는 마이크로 서비스 사이의 요청은 구성 및 정책에 따라 올바른 마이크로 서비스로 라우팅해야합니다.
로드 밸런싱 : 각 마이크로 서비스의 인스턴스는 확장 성을 지원하기 위해로드 밸런싱이 필요하며로드 밸런싱의 세밀성 및 구성은 각 서비스를 관리하는 팀에 의해 제어되어야합니다.
서비스 발견 : 서비스는 느슨하게 결합 된 방식으로 검색 가능해야합니다. 서비스 검색은 일반적으로 서비스 레지스트리를 사용하여 구현되며,이 서비스 레지스트리에서 마이크로 서비스 소유자는 런타임에 다른 서비스가 필요로하는 정보를 등록 및 구성하여 찾아서 호출 할 수 있습니다. 이것을 네트워크 수준의 DNS와 유사하게 생각할 수 있습니다. 서비스 발견은 또한 마이크로 서비스간에 존재할 종속성을 관리하는 데 도움을 주며 환경 변화를 관리 할 때 중요합니다.
구성 저장소 : 서비스 인스턴스는 마이크로 서비스와 전체 환경과 관련된 구성을 공유해야합니다. 예를 들어 환경에 배포 된 마이크로 서비스에는 서비스 검색 레지스트리의 위치와 로그 이벤트를 내보내는 위치를 파악하는 방법이 필요합니다. 마이크로 서비스 환경의 분산 특성으로 인해 분산 키 - 값 저장소를 사용하여 구현되는 경우가 많습니다.
ID 공급자 : 서비스 인스턴스는 신뢰할 수있는 ID를 사용하여 통신해야합니다 ( "ID를 Microservices로 작성"참조 ). 서비스 메시는 이러한 ID를 제공하고 유효성을 검사합니다. 여기에는 외부 ID 공급자 또는 디렉터리와의 통합이 포함될 수 있습니다.
㉣서비스 이미지 레지스트리 :사용자 환경의 어딘가에는 빌드되고 테스트 된 서비스의 불변 이미지를 저장하는 레지스트리가 있습니다. 이 저장소에 사용되는 기술은 사용하는 배포 단위에 따라 다릅니다. 코드 저장소 (동적으로 생성 된 서비스의 경우), Docker 이미지 레지스트리, 이진 아티팩트 저장소 또는 VM 이미지의 BLOB (Binary Large Object) 기반 저장소 일 수 있습니다.
㉤메시지 지향 미들웨어 :가장 간단한 MSA 구현은 HTTP와 같은 동기식 프로토콜 또는 gRPC 또는 Thrift와 같은보다 효율적인 프로토콜을 사용하여 지속 가능할 수 있습니다. 그러나 대부분의 MSA는 게시 / 가입 및 화재 및 잊어 버리기와 같은 이벤트 및 메시지 중심 패턴을 지원하기 위해 비동기 메시징 채널이 필요합니다.
㉥빌드 및 테스트 자동화 :MSA의 개발 민첩성 이점은 개발 출력 품질을 극대화하고 전달을 간소화하기 위해 개발주기에서 높은 수준의 빌드 및 테스트 자동화가 필요합니다.
㉦배포 자동화 :개발 민첩성 이점을 완전히 실현하려면 배포를 자동화해야합니다. 새롭거나 향상된 마이크로 서비스의 배포를 자동화 할뿐만 아니라 외부 아키텍처 자체의 변경 자동화 (예 : 배포의 일부로 서비스 라우팅,로드 균형 조정, 서비스 검색 및 서비스 구성 데이터 업데이트)를 지원해야합니다.
㉧플랫폼 자동화 :마이크로 서비스의 런타임 확장 성과 적응성 이점을 실현하려면 외부 아키텍처에 기본 플랫폼과 관련된 자동화 기능 지원이 포함되어야합니다. 여기에는 VM 또는 컨테이너의 프로비저닝 및 각 마이크로 서비스의 실행중인 인스턴스 관리가 포함됩니다.
㉨모니터링 및 경고 :분산 환경은 환경에서 문제가 발생할 때 모니터링 및 경고의 복잡성을 증가시킵니다. 외부 아키텍처는 일관되고 효율적으로이를 수행 할 수있는 기능을 제공해야합니다.
㉩로깅 및 진단 :분산 환경에서 문제가 발생하면 근본 원인을 식별하고 격리하기가 어려울 수 있습니다. 분산 된 프로세스의 추적을 포함하여 자세한 계측 및 진단 분석을 지원함으로써 외부 아키텍처는 마이크로 서비스 팀이 문제를보다 신속하게 분류하고 해결할 수 있도록 지원합니다.
㉪ID 제공 :토큰 기반 서비스를 사용하여 인증 및 권한 부여를 외부화하는 것은 안전한 고객 대 서비스 및 서비스 대 서비스 상호 작용을 보장하는 것이 좋습니다.
Client 편
마이크로서비스에 접근할 수 있는 API는Web, Mobile, Speech, Services, Partners, IoT 등 다양합니다.
Client는 이런 다양한 형태의 API서비스로 호출할 수 있으며 이를 통합하여 처리하는 서비스가 API Gateway입니다.
ⓐ API Gateway는 다음과 같은 형태의 Mediation을 제공합니다.
[그림 2] A Comparison of API Mediation Technologies @ 2018 Gartner, Inc.
위 이미지는 Consumer API vs Inner API간의 Mediation 그리고 Service to Service 간의 Mediation을 설명하고 있습니다.
Consumer API vs Inner API간의 Mediation은 모니터링, 보안, 트래픽 관리, 경량 통합 및 수익 창출 기능이 포함됩니다.
Service to Service 간의 Mediation은 분산 구성 관리, 동적 검색, 요청 라우팅, 로드 균형 조정, 모니터링, 자가 치유 복원 서비스, 인증 및 권한 부여 및 메시지 암호화가 포함됩니다.
Enterprise Gateway는 서비스 주변 진입 점에서 방어의 첫 번째 라인을 제공하고, API 소비자 사이의 트래픽을 관리하고 백엔드 중앙 집중식 모델을 사용합니다. 엔터프라이즈 게이트웨이의 예로는Google Apigee 및 CA API 관리가 있습니다.
microgateway는 API를 엔드 포인트에서 last-mile 방어를 제공하기 위해 분산 모델을 사용합니다. 서비스가 어플리케이션 서버에 전개 될 때 API 소비자와 백엔드 서비스와 서비스사이의 트래픽을 관리합니다. microgateway의 예로Kong과 Tyk가 있습니다.
Service Mesh는 클러스터 컨테이너 시스템에 배치 miniservices 및 microservices에 대한 서비스 간 통신을관리하는 분산 모델을 사용합니다. 서비스 메쉬 기술의 예로는Istio와 Linkerd가 있습니다.
ⓑ Service Mesh는 사실상 마이크로서비스의 핵심이라고 볼 수 있습니다.
[그림 3] Service Mesh Capabilities @ 2018 Gartner, Inc.
Service Mesh는 Miniservice 및 Microservice 환경 내에서 보안, 확장성 및 가용성을 향상시킵니다.
Service Discovery는 동적 발견을 지원하고 트래픽을 가로 채고 정책을 적용함으로써 마이크로 서비스 간의 경량 조정을 제공합니다.
현재 Service Mesh에는 Kerbernetes, PaaS (Service Platform as a PaaS) 또는 유사 탄력적으로 확장 가능한 환경과 같은 관리 컨테이너 클러스터 내의 Miniservice 및 Microservice에 대한 서비스 간 통신 관리가 있습니다.
다만, Service Mesh 기술은 비교적 새롭고 미성숙하는 점과 많은 주류 기업은 서비스 메시 기술에 대한 경험이 없으며 필요한 전문 지식이 유기적으로 개발하기 쉽지 않은지 확실하지 않다는 문제가 있습니다.
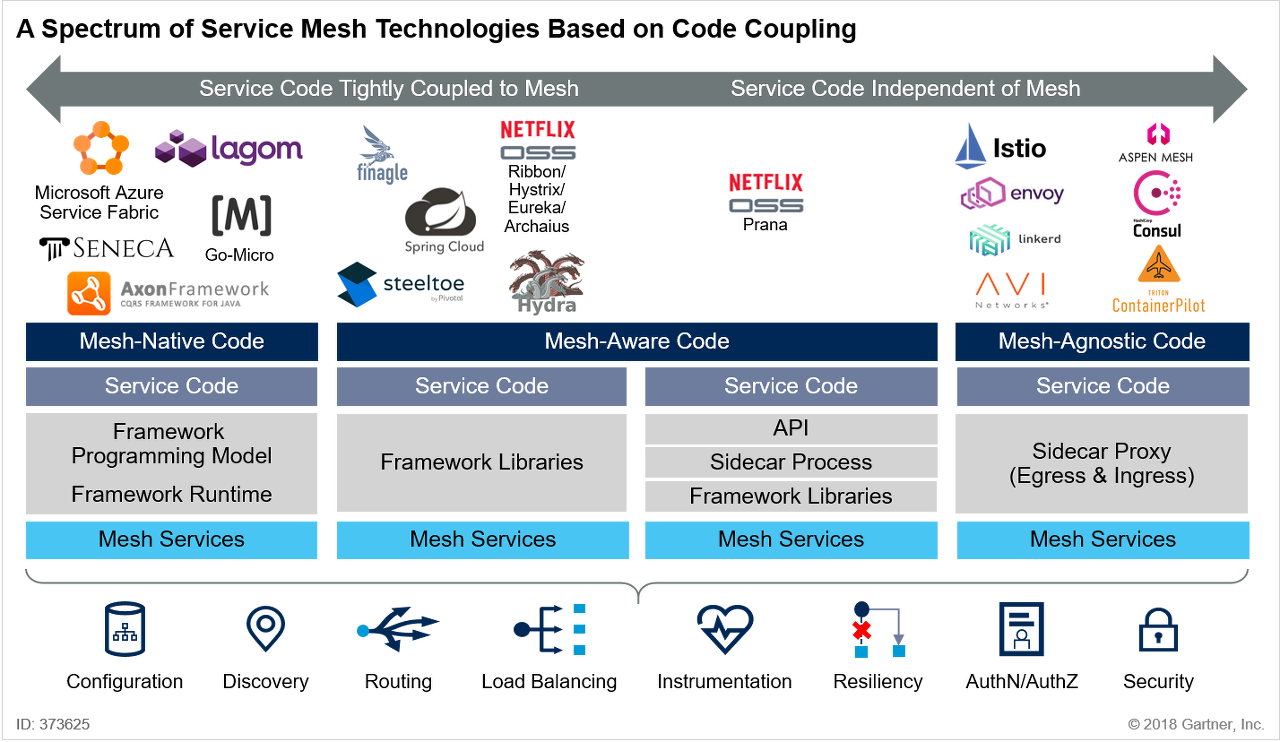
[그림 4] A Spectrum of Service Mesh Technologies Based on Code Coupling @ 2018 Gartner, Inc.
무엇보다 큰 문제는 Lock-in 이슈입니다. Service Mesh는 특히 프레임 워크 또는 라이브러리 기반 솔루션을 사용할 때 lock-in을 생성 할 수 있습니다. Linkerd 또는 Istio와 같은 사이드 카 패턴을 사용하여 배치되는 서비스 메시는 lock-in을 감소시키기 때문에 좋습니다.
사실상 Service Mesh를 대체할 수 있는 기술이 없기 때문에 마이크로서비스를 접하는 모든 IT인이 다루어야 할 기술입니다.
Service Mesh에 대한 설명이 길어졌지만, 결국 API Gateway를 통해 Service Mesh로 전달되면, Service Router를 통해 내부 로드밸러싱을 수행합니다.
이후에는 기존 레가시 서비스와 같이 서비스가 배포 된 Container에서 API를 처리합니다.
이때 성능상의 문제가 생겨서 Container가 또는 Instance가 다운되었을 경우 또는 신규로 생성되었을 경우 Automation 할 수 있는 ServiceDiscovery의 역할을 수행합니다.
Operator 편
운영자는 관리자 계정, 그리고 모니터링, 로깅, 트랜잭션의 관리 조금 더 나아가서 config 관리 및 사용자 관리 수준까지 접근하게 됩니다.
ⓐ Consumer Identity Provider를 통해 관리자 인증을 승인합니다.
ⓑ Telemetry를 통해 Monitoring, Logging, Tracing을 관리하고 제어합니다.
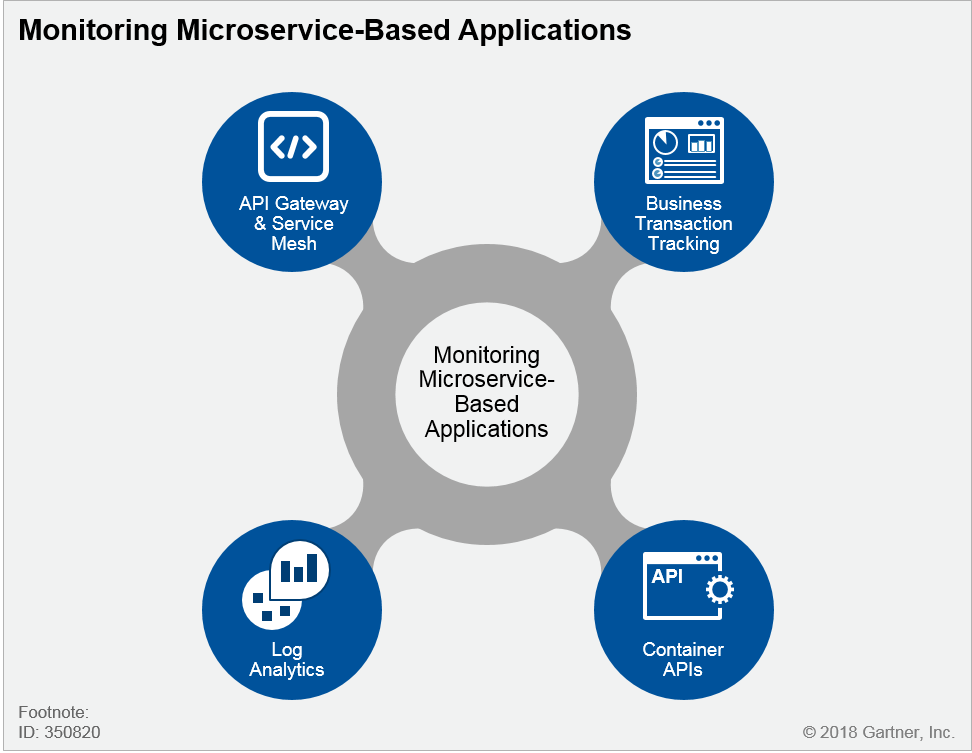
사실상 마이크로서비스를 전환하기위한 요건의 weakness 중 하나인 Monitoring & Diagnostics에 대한 방안을 제시하는 Telemetry입니다.
[그림 5] Monitoring Microservice-Based Applications @ 2018 Gartner, Inc.
Business Transaction Tracking을 어떻게 접근해 나갈 것인가에 대한 고민과 Log를 어떻게 분석해 나갈 것인가에 대한 커다란 문제를 가지고 가지고 접근하게 됩니다. API Gateway이 갖추고 있는 서비스를 연결해 주는 트랜잭션 기능과 sleuth & brave와 같은 application dependency가 추가 되는 방법 중 선택해야 하며, 이중 어떤 기준으로 모니터링하고 로그에 쌓으며 어떠한 로그를 뽑아 낼 것인가에 대한 ELK, EFK등의 추적 방식을 결정해야 합니다.
ⓒ 그밖에 configMap과 같은 configuration을 관리하여 이미지를 재생성하지 않고 컨피그 저장소에 업데이 후 참조하는 방식으로 관리할 수 있는 Service Mesh를 사용합니다.
ⓓ마지막으로 사용자를 관리하는 Identity Provider를 관리하는 역할을 수행합니다.
개발자 편
개발자는 가장 단순한 프로세스를 갖고 있습니다. CI/CD에 대한설계가 나오면 생성 / 배포 하면 끝이기 때문이죠.
ⓐ 먼저 CI/CD Automation을 위한 Build Automation, Image Repository, Deploy Automation을 구축합니다.
다양한 구축 관련 툴을 제시할 수 있지만, 일단 github, jenkins에 대한 범 공용성이 뛰어나니 그 이상의 이야기는 이후 CI/CD를 풀어 낼때 해보도록 하겠습니다.
ⓑ 생성된 이미지를 직접 Instance에 배포하거나 LoadBalancer를 통해 배포하면 모든 과정이 완료됩니다.
이번 포스팅에서는 MSA가 진행될때 운영자, 개발자, Client는 각각 어떠한 마이크로서비스를 타고 수행되는지에 대해 알아보았습니다.
All input coming from user interaction, such mouse click. are directed to the Controller first. The Controller then kick off some functionality. A single Controller may render many different Views based on the operation being executed. Also view doesn’t have any knowledge of or reference to the Controller. Controller interact with the Model and pass the model to the View. So there is a knowledge between the View and Model being passed on to it.
MVP
MVP pattern looks very similar to MVC pattern, but has some key distinctions. In MVP, the input is directed to the View not the Presenter. For each View, there is a dedicated Presenter to render that View. The View hold the reference to the Presenter. The Presenter is also reacting to events being triggered from the View, so its aware of the View its associated with it. The Presenter updates the View with the data from the Model and vice versa. But he View is not aware of the Model.
MVVM
Like MVP pattern, the input is directed to the View. View hold a reference to the ViewModel. But ViewModel is not aware of the View. So it is possible to have one ViewModel to support many Views. You can have a WPF view, Windows Phone or Silverlight View use the same ViewModel. Also the Model is decoupled from the View. ViewModel interact with the Model and feed the View with the data.
Conclusion
This is just a scratch on the surface. This help you at a higher level, to understand the main differences between these 3 pattern. There are lot resources out which explain how to program using these patterns. I will post some more details on these patterns in my future posts.
현재 설정정보 조회 --global옵션은 전역설정에 대한 옵션이며 현재 프로젝트에만 적용할때는 주지 않음
git config --global user.name "사용자명"
사용자명을 등록 (필수)
git config --global user.email "이메일주소"
이메일 주소를 등록 (필수)
git config --global color.ui "auto"
터미널에 표시되는 메시지에 칼라를 표시해줌
git config --global core.editor "vim"
기본 편집 툴을 vim으로 설정함
git config --global merge.tool "vimdiff"
머지 툴을 vimdiff로 설정함
기본 명령어
git --version
현재 git의 버전을 확인
git init
현재 디렉토리에 git 저장소를 생성
git add [파일명]
git add는 2가지를 하는데 untracked files의 파일들을 git가 추적하도록 하거나 파일은 수정했지만 아직 스테이징 영역에 올라가지 않은 파일들을 스테이징 영역에 올림 -i 옵션을 주면 대화형모드가 시작되며 파일의 일부분만 선택해서 스테이징하는 것이 가능 -p 옵션을 사용하면 -i 대화형모드없이 바로 패치모드를 사용할 수 있음
git commit -m "커밋메시지"
스테이징 영역에 올라가 있는 파일들을 커밋 -m 은 커밋메시지를 주는 옵션으로 여러 줄의 커밋메시지를 쓸 경우 -m 을 여러개 사용할 수 있음 -a 옵션을 사용하면 스테이징에 올리는 작업과 커밋을 동시에 할 수 있음 (추적되지 않는 파일은 추가하지 않음) -m을 사용하지 않을때 -v옵션을 사용하면 편집기에 커밋하려는 변경사항의 다른점을 보여줌 특정파일만 커밋하려면 마지막에 파일명을 추가해주면 됨
git commit -C HEAD -a --amend
지정한 커밋의 로그메시지를 다시 사용하여 기존커밋을 수정함 -c를 사용하면 기존메시지를 수정할 수 있는 편집기를 실행해 줌
git status
커밋되지 않은 변경사항을 조회
git diff
스테이징영역과 현재 작업트리의 차이점을 보여줌 --cached 옵션을 추가하면 스테이징영역과 저장소의 차이점을 볼 수 있음 git diff HEAD를 입력하면 저장소, 스테이징영역, 작업트리의 차이점을 모두 볼 수 있음 파라미터로 log와 동일하게 범위를 지정할 수 있으며 --stat를 추가하면 변경사항에 대한 통계를 볼 수 있음
git mv [파일명] [새파일명]
기존에 존재하는 파일을 새파일로 이동함. 변경이력은 그대로 유지
git checkout -- [파일명]
아직 스테이징이나 커밋을 하지 않은 파일의 변경내용을 취소하고 이전 커밋상태로 돌림 svn에서 revert와 동일
Branch와 Tag
git branch
현재 존재하는 브랜치를 조회. -r 옵션을 사용하면 원격저장소의 브랜치를 확인할 수 있음
git branch [브랜치명B] [브랜치명A]
브랜치명A에서 새로운 브랜치 브랜치명B를 만듬 (git에서 기본 브랜치는 master라는 이름을 사용)
git branch [브랜치명]
브랜치명의 새로운 브랜치를 만듬 (체크아웃은 하지 않음)
git branch -d [브랜치명]
브랜치를 삭제
git branch -m [존재하는브랜치명] [새로운브랜치명]
존재하는 브랜치를 새로운브랜치로 변경함 이미 존재하는 브랜치명이 있을 경우에는 에러가 나는데 -M 옵션을 사용하면 이미 있는 브랜치의 경우에도 덮어씀
git tag [태그명] [브랜치명]
브랜치명의 현재시점에 태그명으로 된 태그를 붙힘 git tag만 입력하면 현재 존재하는 태그 목록을 볼 수 있음
git checkout [브랜치명/태그명]
해당 브랜치나 태그로 작업트리를 변경함
git checkout -b [브랜치명B] [브랜치명A]
브랜치명A에서 브랜치명B라는 새로운 브랜치를 만들면서 체크아웃을 함
git rebase [브랜치명]
브랜치명의 변경사항을 현재 브랜치에 적용함
git merge [브랜치명]
브랜치명의 브랜치를 현재 브랜치로 합침 --squash 옵션을 주면 브랜치명의 모든 커밋을 하나의 커밋으로 만듬
git cherry-pick [커밋명]
커밋명의 특정 커밋만을 선택해서 현재 브랜치에 커밋으로 만듬 -n 옵션을 주면 작업트리에 합치지만 커밋은 하지 않기 때문에 여러개의 커밋을 합쳐서 커밋할 수 있음
로그 관리
git log
커밋로그들을 볼 수 있으며 -1나 -2같은 옵션을 주어 출력할 커밋로그의 갯수를 지정할 수 있음 --pretty=oneline 옵션을 주면 한줄로 간단히 보여주고 --pretty=format:"%h %s"처럼 형식을 정해줄 수 있음 -p 옵션을 사용하면 변경된 내용을 같이 보여줌 --since="5 hours" 이나 --before="5 hours"같은 옵션도 사용가능 --graph 옵션을 주면 브랜치 트리를 볼 수 있음
git log [커밋명]
해당 커밋명의 로그를 볼 수 있음 커밋명A..커밋명B (마침표2개)와 같이 입력하면 커밋명A이후부터 커밋명B까지의 로그를 볼 수 있음 ^은 -1과 동일해서 HEAD^라고 하면 최신바로 이전 커밋이고 HEAD^^^와 같이 쓸 수 있으며 HEAD~3을 하면 HEAD의 3개 이전의 커밋을 뜻함
git blame [파일명]
갈 줄 앞에 커밋명과 커밋한 사람등의 정보를 볼 수 있음
git blame -L 10,15 [파일명]
-L 옵션을 사용하면 10줄부터 15줄로 범위를 지정해서 볼수 있고 15대신 +5와 같이 사용할 수 있음 숫자의 범위 대신 정규식도 사용이 가능함
git blame -M [파일명]
-M 옵션을 사용하면 반복되는 패턴을 찾아서 복사하거나 이동된 내용을 찾아줌 -C -C 옵션을 사용하면 파일간의 복사한 경우를 찾아줌 -C -C는 git log에서도 사용가능하며 내용의 복사를 찾을때는 git log에서 -p옵션을 사용함
git revert [커밋명]
기존의 커밋에서 변경한 내용을 취소해서 새로운 커밋을 만듬 -n옵션을 사용하면 바로 커밋하지 않기 때문에 revert를 여러번한 다음에 커밋할 수 있음 (항상 최신의 커밋부터 revert해야 함)
git rebase -i 커밋범위
-i옵션으로 대화형모드로 커밋 순서를 변경하거나 합치는 등의 작업을 할 수 있음
원격저장소
git clone [저장소주소] [폴더명]
원격저장소를 복제하여 저장소를 생성 폴더명은 생략가능
git fetch
원격저장소의 변경사항을 가져와서 원격브랜치를 갱신
git pull
git fetch에서 하는 원격저장소의 변경사항을 가져와서 지역브랜치에 합치는 작업을 한꺼번에 함 파라미터로 풀링할 원격저장소와 반영할 지역브랜치를 줄 수 있음
git push
파라미터를 주지 않으면 origin 저장소에 푸싱하며 현재 지역브랜치와 같은 이름의 브랜치에 푸싱함 --dry-run 옵션을 사용하면 푸싱된 변경사항을 확인할 수 있음 로컬에서 tag를 달았을 경우에 기본적으로 푸싱하지 않기 때문에 git push origin 태그명이나 모든 태그를 올리기 위해서 git push origin --tags를 사용해야 함
git remote add [이름] [저장소주소]
새로운 원격 저장소를 추가함
git remote
추가한 원격 저장소의 목록을 확인할 수 있음
git remote show [이름]
해당 원격 저장소의 정보를 볼 수 있음
git remote rm [이름]
원격저장소를 제거
서브모듈
git submodule
연관된 하위모듈을 확인할 수 있음
git submodule add [저장소주소] [서브모듈경로]
새로운 하위모듈을 해당경로에 추가 추가만하고 초기화는 하지 않으며 커밋 해쉬앞에 마이나스(-)표시가 나타남